AELIA LAELIA CRISPIS
L'Alfabeto della Vita, l'alfabeto universale.

Le proteine (dal greco proteios, "primario") sono i componenti principali di tutte le cellule degli organismi viventi. Secondo alcune stime, nell'uomo ci sono circa 100.000 proteine diverse, delle quali solo il 2% è stato finora descritto adeguatamente. Esse svolgono la maggior parte delle funzioni vitali, costituiscono gli enzimi, che presiedono a tutte le trasformazioni chimiche delle cellule, svolgono diverse funzioni strutturali, sono responsabili del movimento e della contrazione muscolare, presiedono a tutti i fenomeni di trasporto e svolgono ruoli importantissimi nella difesa dell'organismo da agenti estranei. Una proteina è una catena costituita da molecole organiche di piccole dimensioni chiamate amminoacidi. Tutte le proteine conosciute sono formate dalla combinazione di soli 20 tipi di amminoacidi.
Ogni amminoacido ha un atomo centrale di carbonio, che è conosciuto come carbonio alfa, o Ca. All'atomo Ca sono legati un atomo di idrogeno, un gruppo amminico (NH2), un gruppo carbossilico (COOH), e una catena laterale. E' la catena laterale che distingue un amminoacido da un altro. Le catene laterali possono essere semplici come un singolo atomo di idrogeno o complicate.
In una proteina, gli amminoacidi sono legati tra loro attraverso il legame peptidico. Nel processo di formazione del legame viene liberata una molecola d'acqua, perché l'ossigeno e l'idrogeno del gruppo carbossilico si legano ad uno di idrogeno del gruppo amminico. Perciò, quello che troviamo, in realtà, all'interno di una catena polipeptidica è un residuo dell'amminoacido originale. In generale si parla di una proteina avente 100 residui, piuttosto che 100 amminoacidi. Le combinazioni pressoché infinite in cui si possono allineare gli amminoacidi e la forma tridimensionale che può assumere il filamento proteico contribuiscono a spiegare la grande diversità di compiti svolti dalle proteine negli organismi viventi.
Una singola catena proteica può essere costituita da un centinaio fino ad alcune migliaia di amminoacidi che possono combinarsi in tutte le sequenze possibili. E’ assai difficile conoscere dettagliatamente tutte le proteine, ma, nonostante ciò, oggi è nota la struttura primaria - cioè la sequenza amminoacidica - di oltre 4.000 proteine.
Con il termine "struttura primaria" si indicano gli amminoacidi che formano una determinata proteina e la loro sequenza. Le caratteristiche chimico-fisiche di questa molecola, però, sono influenzate anche da come la sua struttura primaria si dispone nello spazio. Infatti, le interazioni tra i gruppi molecolari di una proteina fanno sì che la catena lineare di amminoacidi si ripieghi in una struttura tridimensionale. Quest'ultima si può poi combinare con altre catene, a dare origine ad una proteina complessa.
La sequenza specifica degli amminoacidi determina la struttura primaria di una proteina e contribuisce alla sua forma tridimensionale. Tuttavia, poiché in una molecola proteica vi sono diverse catene laterali, l'interazione dei vari gruppi con l'acqua o tra di loro fa sì che la catena polipeptidica assuma una struttura più o meno ripiegata, detta struttura secondaria e terziaria, che le conferisce una conformazione specifica.
La determinazione della ripiegatura cioè della struttura tridimensionale di una proteina è una delle principali aree di ricerca della biologia molecolare.
Ogni amminoacido ha un atomo centrale di carbonio, che è conosciuto come carbonio alfa, o Ca. All'atomo Ca sono legati un atomo di idrogeno, un gruppo amminico (NH2), un gruppo carbossilico (COOH), e una catena laterale. E' la catena laterale che distingue un amminoacido da un altro. Le catene laterali possono essere semplici come un singolo atomo di idrogeno o complicate.
In una proteina, gli amminoacidi sono legati tra loro attraverso il legame peptidico. Nel processo di formazione del legame viene liberata una molecola d'acqua, perché l'ossigeno e l'idrogeno del gruppo carbossilico si legano ad uno di idrogeno del gruppo amminico. Perciò, quello che troviamo, in realtà, all'interno di una catena polipeptidica è un residuo dell'amminoacido originale. In generale si parla di una proteina avente 100 residui, piuttosto che 100 amminoacidi. Le combinazioni pressoché infinite in cui si possono allineare gli amminoacidi e la forma tridimensionale che può assumere il filamento proteico contribuiscono a spiegare la grande diversità di compiti svolti dalle proteine negli organismi viventi.
Una singola catena proteica può essere costituita da un centinaio fino ad alcune migliaia di amminoacidi che possono combinarsi in tutte le sequenze possibili. E’ assai difficile conoscere dettagliatamente tutte le proteine, ma, nonostante ciò, oggi è nota la struttura primaria - cioè la sequenza amminoacidica - di oltre 4.000 proteine.
Con il termine "struttura primaria" si indicano gli amminoacidi che formano una determinata proteina e la loro sequenza. Le caratteristiche chimico-fisiche di questa molecola, però, sono influenzate anche da come la sua struttura primaria si dispone nello spazio. Infatti, le interazioni tra i gruppi molecolari di una proteina fanno sì che la catena lineare di amminoacidi si ripieghi in una struttura tridimensionale. Quest'ultima si può poi combinare con altre catene, a dare origine ad una proteina complessa.
La sequenza specifica degli amminoacidi determina la struttura primaria di una proteina e contribuisce alla sua forma tridimensionale. Tuttavia, poiché in una molecola proteica vi sono diverse catene laterali, l'interazione dei vari gruppi con l'acqua o tra di loro fa sì che la catena polipeptidica assuma una struttura più o meno ripiegata, detta struttura secondaria e terziaria, che le conferisce una conformazione specifica.
La determinazione della ripiegatura cioè della struttura tridimensionale di una proteina è una delle principali aree di ricerca della biologia molecolare.
Il codice genetico

Le proteine sono prodotte in una struttura cellulare chiamata ribosoma. I ribosomi sono dei piccoli organuli costituiti da RNA e proteine. Svolgono la funzione di assemblare le proteine, secondo le istruzioni contenute in una molecola chiamata acido ribonucleico messaggero (o RNA messaggero). Essi operano come se fossero delle microscopiche catene di montaggio. L’RNA messaggero trasporta ai ribosomi l’informazione contenuta nel DNA, che rimane al sicuro, ben protetto, all’interno del nucleo della cellula. Le informazioni genetiche codificate nel DNA, sigla dell’acido desossiribonucleico, ordinano la sintesi di tutti i tipi di proteine necessarie alla vita degli organismi.
Il codice genetico è una sorta di linguaggio molecolare, basato sull’ordine in cui si susseguono quattro diverse basi azotate.
In pratica, il DNA dispone di un alfabeto di quattro lettere (c,t,a,g) per specificare i circa 20 amminoacidi da cui possono essere costituite, secondo un preciso ordine di successione, le proteine.
Il codice genetico è una sorta di linguaggio molecolare, basato sull’ordine in cui si susseguono quattro diverse basi azotate.
In pratica, il DNA dispone di un alfabeto di quattro lettere (c,t,a,g) per specificare i circa 20 amminoacidi da cui possono essere costituite, secondo un preciso ordine di successione, le proteine.
Citosina e timina, le stelle di Davide
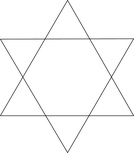
Le basi azotate più leggere, citosina e timina, hanno gli atomi di carbonio e azoto disposti in una molecola a struttura "esagonale" ma sarebbe meglio dire ai vertici di una stella di Davide.
Guanina e Adenina, le stelle di Lucifero
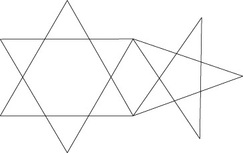
Le basi azotate più pesanti, Adenina e Guanina, possiedono la stessa struttura esagonale a cui si aggiunge una struttura pentagonale (ai vertici di una stella a 5 punte) che insiste su uno dei lati dell’esagono. Gli atomi sono posti in corrispondenza degli angoli di un esagono e di un pentagono cioè in corrispondenza delle cuspidi di una stella a 6 punte e di una a 5 punte.
Le possibile combinazioni della 4 lettere di base danno 64 combinazioni che quindi sono più che sufficienti per codificare i 20 amminoacidi. Il codice per un dato amminoacido è formato dalla successione di tre basi azotate, che viene detta tripletta o codone. Ad esempio se nel DNA vi sono di seguito le basi azotate atg seguite da gac significa che darà codificata una proteina fatta dalla Metionina M e dalla Asparagina D.
L’ordine in cui si susseguono le triplette corrisponde all’ordine in cui le rispettive molecole di amminoacidi si dispongono nella catena della proteina.
Poiché esistono 64 triplette possibili e solo 20 amminoacidi, il codice genetico è ridondante. Alcuni amminoacidi possono infatti essere codificati da più triplette. Non è invece vero il contrario: ad ogni tripletta corrisponderà un solo amminoacido, senza possibilità di equivoci. Esistono infine tre triplette che non codificano alcun amminoacido, ma rappresentano le istruzioni di fine-paragrafo ovvero indicano il punto in cui, all'interno del gene, termina la sequenza che codifica la proteina corrispondente: si tratta dei codoni TAA, TGA e TAG.
L’inizio paragrafo è invece dato dall’amminoacido M (metionina) codificato dal codone aug.
La ridondanza rende la sintesi proteica molto più stabile di quanto non sarebbe stata se ad un amminoacido fosse corrisposto una ed una sola tripletta di basi azotate.
Sono solo due gli amminoacidi codificati da un unico codone. Sono la metionina, codificata da AUG che è anche il codone di avvio, ed il triptofano, codificato da tgg
Il tratto di DNA in cui sono codificate le istruzioni per la sintesi di una proteina è detto gene.
Il codice genetico è sorprendentemente universale ed è ugualmente valido sia per i virus che per i batteri che per gli animali superiori e per l’uomo.
Il codice della vita, ed il suo alfabeto, danno origine a una sequenza lineare di lettere e di paragrafi. I codoni di avvio e di fine svolgono la funzione di inizio paragrafo e di fine paragrafo, cioè di marcare l’inizio e la fine della proteina. Ogni proteina è quindi come se fosse un paragrafo di un libro. Tutta l’informazione necessaria alla vita sul nostro pianeta è contenuta in geni che sono fatti di lunghe sequenze di lettere. Tutta la vita sulla Terra è basta sullo stesso alfabeto universale di 20 amminoacidi, codificati da 4 basi azotate. La vita è costruita esattamente con un libro, in cui si usa sempre lo stesso alfabeto e la stessa lingua.
Le possibile combinazioni della 4 lettere di base danno 64 combinazioni che quindi sono più che sufficienti per codificare i 20 amminoacidi. Il codice per un dato amminoacido è formato dalla successione di tre basi azotate, che viene detta tripletta o codone. Ad esempio se nel DNA vi sono di seguito le basi azotate atg seguite da gac significa che darà codificata una proteina fatta dalla Metionina M e dalla Asparagina D.
L’ordine in cui si susseguono le triplette corrisponde all’ordine in cui le rispettive molecole di amminoacidi si dispongono nella catena della proteina.
Poiché esistono 64 triplette possibili e solo 20 amminoacidi, il codice genetico è ridondante. Alcuni amminoacidi possono infatti essere codificati da più triplette. Non è invece vero il contrario: ad ogni tripletta corrisponderà un solo amminoacido, senza possibilità di equivoci. Esistono infine tre triplette che non codificano alcun amminoacido, ma rappresentano le istruzioni di fine-paragrafo ovvero indicano il punto in cui, all'interno del gene, termina la sequenza che codifica la proteina corrispondente: si tratta dei codoni TAA, TGA e TAG.
L’inizio paragrafo è invece dato dall’amminoacido M (metionina) codificato dal codone aug.
La ridondanza rende la sintesi proteica molto più stabile di quanto non sarebbe stata se ad un amminoacido fosse corrisposto una ed una sola tripletta di basi azotate.
Sono solo due gli amminoacidi codificati da un unico codone. Sono la metionina, codificata da AUG che è anche il codone di avvio, ed il triptofano, codificato da tgg
Il tratto di DNA in cui sono codificate le istruzioni per la sintesi di una proteina è detto gene.
Il codice genetico è sorprendentemente universale ed è ugualmente valido sia per i virus che per i batteri che per gli animali superiori e per l’uomo.
Il codice della vita, ed il suo alfabeto, danno origine a una sequenza lineare di lettere e di paragrafi. I codoni di avvio e di fine svolgono la funzione di inizio paragrafo e di fine paragrafo, cioè di marcare l’inizio e la fine della proteina. Ogni proteina è quindi come se fosse un paragrafo di un libro. Tutta l’informazione necessaria alla vita sul nostro pianeta è contenuta in geni che sono fatti di lunghe sequenze di lettere. Tutta la vita sulla Terra è basta sullo stesso alfabeto universale di 20 amminoacidi, codificati da 4 basi azotate. La vita è costruita esattamente con un libro, in cui si usa sempre lo stesso alfabeto e la stessa lingua.
